
인공지능? 머신러닝? 딥러닝?
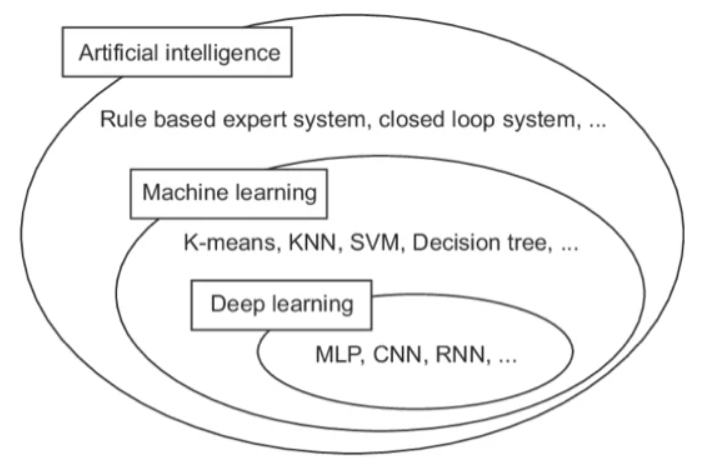
- 인공지능: 지능적인 요소가 포함된 기술을 총칭
- 머신러닝: 인공지능 분야에서 특정 종류의 기술을 따로 묶어 부르는 것으로 알고리즘을 이용해 데이터를 분석 및 학습하며 학습한 내용을 기반으로 판단하여 예측하는 것
- 딥러닝: 머신러닝의 방법론 중 하나
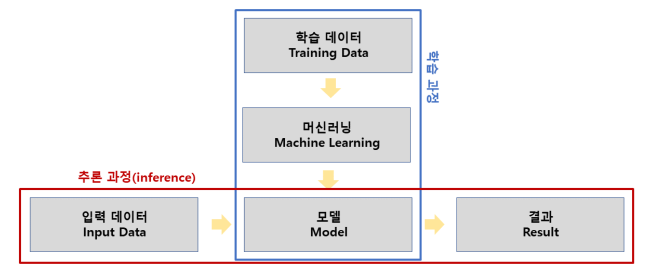
머신러닝이란
- "데이터에서 모델을 찾아내어 결과를 추론하는 기법"
- 머신러닝으로 얻어내는 최종 결과물은 "모델"
- 영상, 음성, NLP 등 지능과 관련된 분야가 전통적인 방식으로는 모델링하기 힘든 대표적 분야다
머신러닝의 장점
- 복잡한 패턴을 인지할 수 있다
- 적절한 알고리즘, 다양한 양질의 데이터가 있다면 좋은 성능을 낼 수 있다
- 도메인 영역에 대한 지식이 상대적으로 부족해도 활용할 수 있다
머신러닝의 어려움
1. 데이터를 이용해 모델을 학습하는 기법으로 근원적인 문제 또한 이 "데이터"로부터 파생된다
- 데이터의 의존성이 크다. "Garbage in, Garbage out"
- 학습 데이터와 입력 데이터의 차이가 머신러닝의 구조적인 난제다
2. 과적합의 오류에 빠질 수 있다 (일반화 오류, 데이터 다양성 요구)
3. 풍부한 양질의 데이터(high quality, high quantity)가 기본적으로 요구된다
4. 데이터, 예측해야 할 값에 맞는 적절한 알고리즘을 사용해야 한다
일반화(generalization)
- 학습 데이터와 입력 데이터가 달라져도 성능 차이가 나지 않게 하는 해결하는 것을 뜻한다
- 머신러닝의 성패는 이 일반화를 얼마나 잘 달성했는가에 달려 있다고 해도 무방하다
과적합(overfitting)
- 일반화 성능을 떨어뜨리는 주범이다
- 전투에서 이겼지만 전쟁에서 진 격이다
- 학습 데이터는 완벽하지 않으며 잡음이 섞일 수 있으나 학습 과정에서 학습 데이터가 모두 정답이라고 생각하고 모델링을 하면 발생되는 현상을 뜻한다
과적합에 대한 해결책
- 정칙화(regularization), 검증(validation)이 과적합에 대항하는 대표적인 기법이다
- 정칙화: simple is the best. 모델을 간단하게.
- 검증: 학습 데이터의 일부를 떼어내어 학습에 포함시키지 않고, 검증용으로 활용하는 것이다
- 교차검증: 검증용 데이터를 고정하지 않고 무작위로 바꾸는 검증을 변형한 기법이다
머신러닝의 종류
- 학습 방식에 따라:

- 지도 학습
- 학습 데이터는 {입력, 정답(레이블)}
- '입력'에 대한 모델의 출력과 해당 '정답'의 차이가 줄도록 모델을 수정하는 과정
- 완벽하게 학습이 가능하다
- 비지도 학습
- 학습 데이터는 {입력}
- 주로 데이터의 특성을 이해하거나 데이터를 가공하는 데 사용된다
- 대표적인 기법: 군집화(clustering), 차원 축소(dimentionality reduction)
- 강화 학습
- 학습데이터는 {입력, 출력, 출력에 대한 평가 점수}
- 주로 제어, 게임 등 상호작용을 통해 최적의 동작을 학습해야 할 때 사용된다
지도학습 -- 분류와 회귀
- 지도학습에서 모델의 쓰임새에 따라 "분류(classification)"와 "회귀(regression)"로 나눌 수 있다
- 분류
- 입력 데이터가 어느 범주에 속하는지를 알아내는 문제에 사용된다
- 학습 데이터는 {입력, 해당 범주}
- 회귀
- 수치형 값을 예측하는 게 목표다
- 학습 데이터는 {입력, 값}
- '군집화(clustering)'는 비지도 학습으로 완전히 다른 기법이다
가설함수, 비용, 손실함수
- 예측의 근간이 되는 가설함수 H(x) = W * x + b 를 세운다
- 가지고있는 x와 y의 값을 기준으로 다양한 trial을 통해 W와 b를 예측한다
- 손실함수를 계산한다

- 가설함수 $H(x)=Wx+b$
- 이 $H(x)$를 $y$ $predict$라고 부른다
- 손실 $=y-y$ $predict$
- 손실함수 $=y-(Wx+b)$
- 손실의 합이 0에 가까울수록 좋은 예측이다.
따라서, 손실함수 $=y-(Wx+b)=y-(2x+1)$
- 부호의 문제가 있으므로 squared를 이용한다
손실함수 $=\Sigma(y-(Wx+b))^2$
- 데이터의 개수가 많아지면 손실이 커지므로 전체 손실의 평균을 구한다
$\quad\rightarrow$ Mean Squared Error
$$손실함수=\frac{\Sigma(y-(Wx+b))^2}{n}$$

- 손실이 최소가 되는 지점을 찾는 것 = 최적의 W를 찾는 것 = 최소 오차
$\quad\rightarrow$ 경사하강범 (Gradient Descent): 초기 W값을 넣고 global cost minimum으로 내리는 것 (미분)

딥러닝 첫걸음 (한빛미디어, 2017), 패스트캠퍼스 강의 등을 참고하여 정리했습니다.